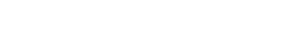

uniqはファイルから重複する行を削除するコマンドだ。
uniqはカタカナではユニークで、「唯一の」「1つしかない」という意味だ。
コンピュータの世界では「ユニークなデータ」は「重複していないデータ」を意味する。
uniqコマンドの基本
コマンドの基本動作
uniqコマンドで処理するファイルは、あらかじめ並べ替えされていなければならないので、sortコマンドなどで並べ替えをしておこう。
使い方は、次のとおりだ。
$ uniq 元ファイル名
ファイルs.datから重複行を削除する場合は、次のコマンドだ。
$ uniq s1.dat
ファイルs1.datから重複行が削除された内容が表示された。
出力ファイル名を指定して、結果を別ファイルに書き出すことも可能だ。
$ uniq 元ファイル名 出力先ファイル名
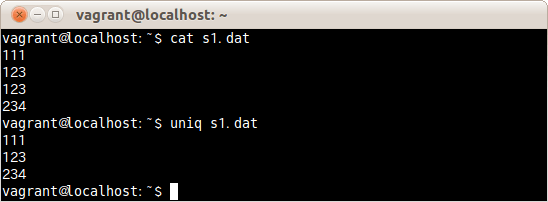
ファイルs.datから重複行を削除した結果をファイルs2.datに出力する場合は、次のコマンドだ。
$ uniq s1.txt s2.dat
ファイルs1.datから重複行が削除されたファイルがs2.datに記録され、その内容が表示された。
uniqコマンドのオプションたち
オプションの一覧
後から詳細をご紹介するが、まずは一覧で見てみよう。
オプション -c(オプション--count)
重複した行数も表示する。
オプション -d(オプション--repeated)
重複した行を表示する。
オプション -D(オプション--all-repeated)
重複した行をすべて表示する。
オプション -u(オプション--unique)
重複した行は一切表示しない。
オプション -f(オプション--skip-fields=N)
指定した項目以降で重複を判断する。
オプション -w(オプション--check-chars=N)
指定した文字数までで重複を判断する。
では一つずつ見ていこう。
-cオプション:(--countオプション):重複した行数も表示する
重複行を削除し、重複した行数も表示する書式は次のとおりだ。
$ uniq -c 元ファイル名
ファイルs1.datの重複行を削除し、重複した行数も表示する場合は、次のコマンドだ。
$ uniq -c s1.dat
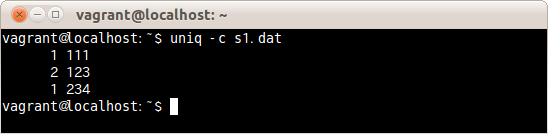
ファイルs1.datの重複行が削除され、重複した行数が表示された。
-dオプション(--repeatedオプション):重複した行を表示する
重複した行のみを表示するオプションで書式は次の通りだ。
$ uniq -d 元ファイル名
ファイルs1.datの重複した行のみを表示する場合は、次のコマンドだ。
$ uniq -d s1.dat
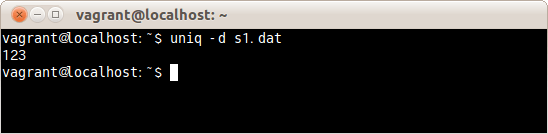
ファイルs1.datの重複した行のみが表示された。
-Dオプション(--all-repeatedオプション):重複した行をすべて表示する
重複した行を1行だけではなく、すべての行を表示するオプションで、書式は次の通りだ。
$ uniq -D 元ファイル名
ファイルs1.datの重複した行をすべて表示する場合は、次のコマンドだ。
$ uniq -D s1.dat
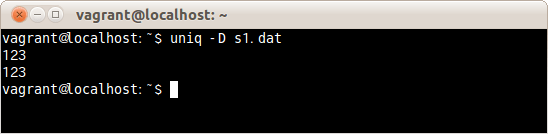
ファイルs1.datの重複した行をすべてが表示された。
-uオプション(--uniqueオプション):重複した行は一切表示しない
重複した行は表示せず、重複しなかった行のみを表示するオプションで書式は次の通りだ。
$ uniq -u 元ファイル名
ファイルs1.txtの重複しなかった行のみを表示する場合は、次のコマンドだ。
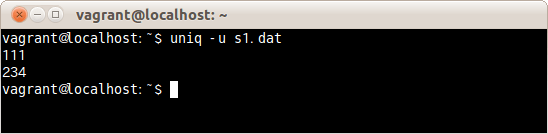
ファイルs1.txtの重複しなかった行のみを表示した。
-fオプション(--skip-fields=Nオプション):指定した項目以降で重複を判断する
行全体ではなく、スペースやタブ文字で区切られた項目で重複を判断する。
書式は次の通りだ。
$ uniq -f 項目の位置 元ファイル名
1項目めは番号、2項目めは商品名、3項目めは単価、4項目めに売上個数が入力されているテキストファイルがある。
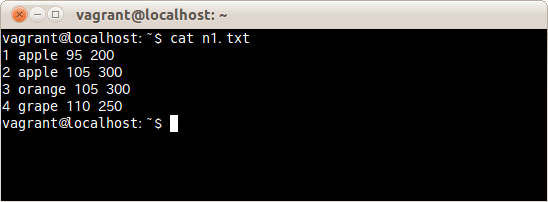
項目の位置は1少ない数字となり、1項目めなら0、3項目めなら2だ。
ファイルn1.txtの3項目め以降が重複していたら、重複行を削除するコマンドは次の通りだ。
$ uniq -f 2 n1.txt
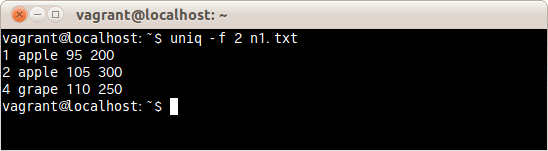
ファイルn1.txtの3項目め以降が2行目と重複している3行目が削除された。
-wオプション(--check-chars=Nオプション):指定した文字数までで重複を判断する
-fオプションと併用して使うのが一般的だが、指定した文字数までで重複を判断する。
書式は次の通りだ。
$ uniq -f 項目の位置 -w 文字数 元ファイル名
文字数は指定したい文字数よりも1多い数字となる。
ファイルn1.txtの3項目めの1文字が重複していたら、重複行を削除するコマンドは次の通りだ。
$ uniq -f 2 -w 2 n1.txt
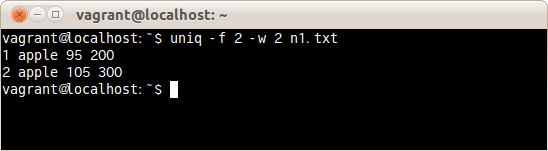
ファイルn1.txtの3項目めの1文字以降が1という文字で2行目と重複している3行め、4行めを削除した。
uniq関連コマンド
最後にuniqコマンドに関連して、基本的なテキスト処理のコマンドも紹介しておく。
sortコマンド
テキストファイルを並べ替えする。
cutコマンド
文字列を分離する。
まとめ
このページでは、uniqコマンドを使ったテキストファイルから重複行を削除のする方法を解説した。
ログやデータベースのデータを整理する時に活用できる。
簡単なコマンドなので覚えて活用しよう。



コメント