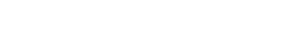

XMLとは、データをシンプルに扱うためのデータの構造だ。使いやすい構造になっており、特にWebでは重宝されるサービスになっている。
このページではXMLとは何かについてお伝えし、JavaでXMLを扱う方法についてもまとめてお伝えする。参考にしていただければと思う。
目次
XMLとは何か?
XML(eXtensible Markup Language)は、シンプルにデータの構造を表わすために考えられた言語である。言語というと難しそうだが、データを表現する方法という意味で言語という言葉が使われている。最初は、大規模な電子出版のために設計されたが、現在ではWebなどの分野で様々なデータをやり取りするためにXMLが広く使われている。
例えば、あらかじめXMLで表現された商品データを会計システムからレジにダウンロードしておく。逆に、レジで清算が終わった時、今度はXMLによって表現された会計情報をレジから会計システムに送るといったことが行われている。
XMLが目指すところは次の通りである。
- インターネット上で使いやすい。
- 広く様々なアプリケーションをサポートする。
- XML文書を処理するプログラムを簡単に書ける。
- オプションとなる機能を可能な限りゼロにする。
- 規則に従ったもので簡潔である
- 人が読みやすく、道理にかなった範囲で分かりやすい。
- XML文書はすぐに作成できる。
では、この目標のもとに開発されたXMLがどのようなものか、実際にXMLで書かれたレシートの例を見てみよう。
XMLドキュメント
XMLで書かれたデータをXMLドキュメント(Document)という。XMLドキュメントは要素(Element)で構成されている。要素の書き方はシンプルである。
<要素名 属性=”値”>内容</要素名>
<要素名>が要素の開始であり、</要素名>が要素の終了になる。この開始と終了の間に内容が記述される。属性を付けることもできるようになっている。
シンプルなXML
シンプルなレシートのデータを例に考えみよう。値段や個数などは省いて、買い物した商品ひとつだけのレシートである。ここでは、その品物の要素名を商品(item)とする。「りんご」ひとつのを買った時のレシートを、XMLで記述すると次のようになる。
<Item>りんご</Item>
加えて、XMLドキュメントの先頭行にはXML宣言が必要である。それで、実際のレシートのXMLドキュメントは最終的にこのようになる。
<?xml version="1.0" encoding="UTF-8"?> <item>みかん</item>
複数の要素を持つXML
XML文書は最上位の要素(Document Elementと呼ぶ)を一つだけ持つという規則がある。最上位の要素は、複数あってはならない。この要素の中にXMLドキュメントの要素がすべて入る。
例えば要素がふたつになると、要素をふたつ並べるだけでなく、ふたつの要素を入れるための最上位の要素を用意して、その中にふたつの要素を並べるということになる。それで、レシート(receipt)という要素を最上位にして、その中に商品(item)という要素を入れた。
<?xml version="1.0" encoding="UTF-8"?>
<receipt>
<item>りんご</item>
<item>みかん</item>
</receipt >
複雑なXML
実際のレシートを表現するために必要な要素を盛り込んだ。レシートの中には買い物をした商品だけでなく、お店の情報などがあるはずだ。
最上位の要素(receipt)の中にお店(shop)と商品群(items)と入れた。そして、商品群(items)中に買い物した商品(item)をその数だけ入れるようにした。さらに、お店の要素には、お店のidを要素の属性として加えた。
<?xml version="1.0" encoding="UTF-8"?>
<receipt>
<shop id="0123">ABC店</shop>
<items>
<item>りんご</item>
<item>みかん</item>
</items>
</receipt >
JavaでXMLを扱うためのDOMとSAX
JavaでXMLを扱うために、DOM(Document Object Model)とSAX(Simple API For XML)が用意されている。それぞれ特徴があるので、その概要を見てみよう。
SAXの概要
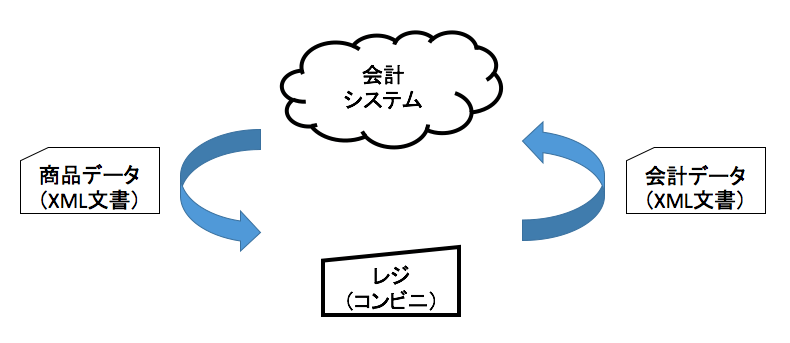
SAXはXMLドキュメントを読み込みながら、要素をひとつ読み込むごとにイベントとしてプログラムに知らせてくれる。プログラムは、このイベントと共に要素や属性を受け取って、イベントに対応するメソッドで処理することができるようになっている。
DOMの概要
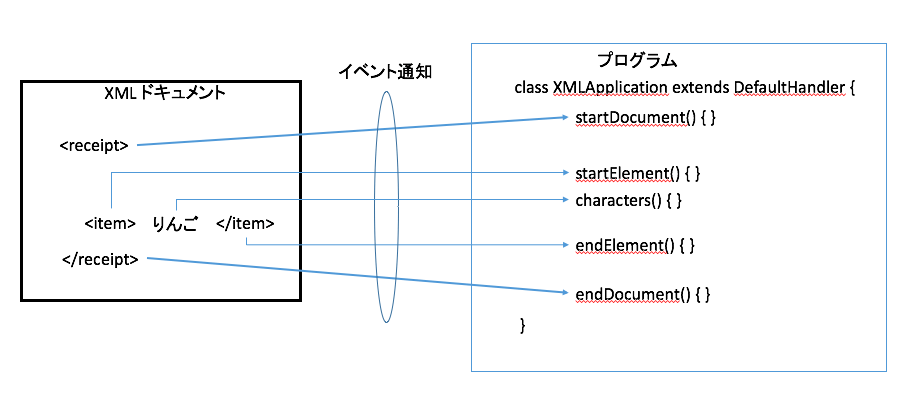
DOMはXMLドキュメントを読み込んで解析し、ドキュメントと呼ばれるノードツリーを作る。要素がノードで表され、ノードの関係がノードツリーで表されている。ノードツリーが作られると、その中の要素をDOMのAPIでノードとして扱うことができる。

では、SAXのAPI仕様から見てみよう。
SAX API仕様
SAX Parserの準備をする
SAX Parserの準備は、以下のステップで行われる。
ステップ1:DOMのAPIを使うために最初に使うのが、SAXParserFactoryクラスのstaticメソッドnewInstance()である。
SAXParserFactory.newInstance()
|
戻り値の型 |
public static SAXParserFactory |
|
内容 |
SAXParserFactoryの新しいインスタンスを得る。このstaticメソッドは新しいインスタンスを生成する。
メソッドが提供されているクラス:SAXParserFactoryクラスは、パッケージjavax.xml.parsersにある。 アプリケーションが、XMLドキュメントを構文解析するためにSAXに基づくパーサーを初期設定し、取得することを可能にする、
戻り値:SAXParserFactoryの新しいインスタンス。 例外: FactoryConfigurationError – サービス構成エラーか、もし実装がされていないか、インスタンスが生成できない場合。 |
ステップ2:SAXParserFactoryのインスタンスからSAXParserのインスタンスを得るためにメソッドnewSAXParser ()を呼び出す。
newSAXParser ()
|
戻り値の型 |
public abstract SAXParser |
|
内容 |
現在の製造設定パラメータを使ってSAXParserの新しいインスタンスを生成する。
戻り値:SAXParserの新しいインスタンス。 例外: ParserConfigurationException – もし要求された構成情報を満足するパーサーを生成することができない場合。 |
ステップ3:SAXParserのインスタンスに、XMLドキュメントとイベントハンドラーを設定するためにメソッドparse()を呼び出す。そうすると、構文解析が開始され、イベントの通知が始まる。
parse(File f, DefaultHandler dh)
|
戻り値の型 |
public void |
|
内容 |
XMLとして指定されたファイルの内容を指定されたDefaultHandler.を使って構文解析する。
引数: f – 構文解析すべきXMLを含んでいるファイル。 dh – 使用すべきSAX DefaultHandler. 例外: IOException – IOエラーが発生した場合。 SAXException – 構文解析エラーが発生した場合。 |
イベントが通知される
以下に示すAPI仕様は、org.xml.sax.helpersにあるDefaultHandlerクラスが持つメソッドである。アプリケーションはこのDefaultHandlerのサブクラスとして定義することになる。そして、XMLドキュメントを読み込む際に、イベントがDefaultHandlerのサブクラスに通知されることになる。
startDocument()
|
戻り値の型 |
public void |
|
内容 |
ドキュメントの始まりの通知を受け取る。 デフォルトとして何もしない。ドキュメントの始まりで特定のアクション(ルートノードを確保したり出力ファイルを作成したりするような)を取るために、アプリケーションがサブクラスの中でこのメソッドをオーバーライドするかもしれない。 例外: SAXException – すべてのSAXの例外、他の例外を中に持っているかもしれない。 |
endDocument()
|
戻り値の型 |
public void |
|
内容 |
ドキュメントの終わりの通知を受け取る。 デフォルトとして何もしない。ドキュメントの終わりで特定のアクション(ツリーを完了させたり、出力ファイルをクローズしたりするような)を取るために、アプリケーションがサブクラスの中でこのメソッドをオーバーライドするかもしれない。 例外: SAXException – すべてのSAXの例外、他の例外を中に持っているかもしれない。 |
startElement(String uri, String localName, String qName, Attributes attributes)
|
戻り値の型 |
public void |
|
内容 |
要素の始まりの通知を受け取る。 デフォルトとして何もしない。各々の要素の始まりで特定のアクション(ルートノードを確保したり出力ファイルを作成したりするような)を取るために、アプリケーションがサブクラスの中でこのメソッドをオーバーライドするかもしれない。
引数: uri – 名前空間URI。もし名前空間URIを持たないか、もし名前空間処理が実行されないならば空の文字列。 localName – ローカル名(接頭辞なしで)。もし名前空間処理が実行されないならば空の文字列。 qName – 修飾名(接頭辞付きの)。もし限定名が有効でなければ空の文字列。 attributes – 要素に付加された属性。もし属性がなければ、それは空のAttributesオブジェクトとなる。
例外: SAXException – すべてのSAXの例外、他の例外を中に持っているかもしれない。 |
endElement(String uri, String localName, String qName)
|
戻り値の型 |
public void |
|
内容 |
要素の終わりの通知を受け取る。 デフォルトとして何もしない。各々の要素の終わりで特定のアクション(ツリーを完了させたり、出力ファイルをクローズしたりするような)を取るために、アプリケーションがサブクラスの中でこのメソッドをオーバーライドするかもしれない。
引数: uri – 名前空間URI。もし名前空間URIを持たないか、もし名前空間処理が実行されないならば空の文字列。 localName – ローカル名(接頭辞なしで)。もし名前空間処理が実行されないならば空の文字列。 qName – 修飾名(接頭辞付きの)。もし限定名が有効でなければ空の文字列。
例外: SAXException – すべてのSAXの例外、他の例外を中に持っているかもしれない。 |
characters(char[] ch, int start, int length)
|
戻り値の型 |
public void |
|
内容 |
要素の内部の文字データの通知を受け取る。 デフォルトとして何もしない。各々の文字データの固まりのための特定のアクション(データをノードやバッファーに追加したり、ファイルに出力したりするような)を取るために、アプリケーションがサブクラスの中でこのメソッドをオーバーライドするかもしれない。
引数: ch – 文字配列。 start – 文字配列の先頭位置。 array.length – 文字配列から使用できる文字の数。
例外: SAXException – すべてのSAXの例外、他の例外を中に持っているかもしれない。 |
SAXでシンプルなXMLを扱うサンプルプログラム
このサンプルプログラムは、シンプルなXMLドキュメントを読み込んで、その要素を表示する
XMLドキュメントはシンプルなレシートである。
<?xml version="1.0" encoding="UTF-8"?> <item>みかん</item>
このサンプルプログラムはSAXを使っているので、レシートの一行を読むたびにイベントに対応したメソッドが呼び出される。詳細を知るには、プログラムの説明とSAX API仕様を照らし合わせながら学ぶ必要がある。
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class XmlSaxSimpleReader extends DefaultHandler{
public static void main(String[] args) throws IOException, ParserConfigurationException, SAXException {//[1]
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();//[2]
SAXParser saxParser = saxParserFactory.newSAXParser();//[3]
saxParser.parse(new File("C:\\temp\\receipt_one_element.xml"), new XmlSaxSimpleReader());//[4]
}
public void startDocument() {//[10]
System.out.println("[11] ドキュメント開始");
}
public void startElement(String uri, String localName, String qName, Attributes attributes) {//[20]
System.out.println("[21] 要素開始 = " + qName);//[21]
}
public void characters(char[] ch, int offset, int length) {//[30]
System.out.println("[31] テキストデータ = " + new String(ch, offset, length));
}
public void endElement(String uri, String localName, String qName) {//[40]
System.out.println("[41] 要素終了 = " + qName);
}
public void endDocument(){//[50]
System.out.println("[51] ドキュメント終了");
}
}
実行結果
[11] ドキュメント開始 [21] 要素開始 = item [31] 内容 = りんご [41] 要素終了 = item [51] ドキュメント終了
プログラムの説明
- [1] 実行のためのmain()メソッド定義。
- [2]-[4] 構文解析する。(セクション:SAX API仕様→SAX Parserの準備をする→「ステップ1から3」を参照)
- [10][11] ドキュメント開始イベントで、「ドキュメント開始」を表示する。
- [20][21] 要素開始イベントで、「要素開始」を表示する。
- [30][31] 内容を表示する。
- [40][41] 要素終了イベントで、「要素終了」を表示する。
- [50][51] ドキュメント終了イベントで、「ドキュメントの終了」を表示する。
SAXで複数の要素を持つXMLを扱うサンプルプログラム
このサンプルプログラムは、複数の要素を含むXMLドキュメントを読み込んで、その要素を表示する
XMLドキュメントの商品の内容はりんごとみかんのふたつだけのレシートである。
<?xml version="1.0" encoding="UTF-8"?>
<receipt>
<item>りんご</item>
<item>みかん</item>
</receipt>
このサンプルプログラムもSAXを使っているので、レシートの一行を読むたびにイベントに対応したメソッドが呼び出される。詳細を知るには、プログラムの説明とSAX API仕様を照らし合わせながら学ぶ必要がある。
先のサンプルではイベントにフィルターをかけないで、すべて表示した。このサンプルではフィルターをかけて、名前がitemの要素の開始と終了にある内容だけを表示する。
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.File;
import java.io.IOException;
public class XmlSaxTwoItemsReader extends DefaultHandler{
boolean startItem = false;
public static void main(String[] args) throws IOException, ParserConfigurationException, SAXException {//[1]
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();//[2]
SAXParser saxParser = saxParserFactory.newSAXParser();//[3]
saxParser.parse(new File("C:\\temp\\receipt_two_elements.xml"), new XmlSaxTwoItemsReader());//[4]
}
public void startDocument() {//[10]
System.out.println("[11] ドキュメント開始");
}
public void startElement(String uri, String localName, String qName, Attributes attributes) {//[20]
System.out.println("[21] 要素開始 = " + qName);//[21]
if (qName.equals("item"))//[22]
startItem = true;//[23]
}
public void characters(char[] ch, int offset, int length) {//[30]
if (startItem)//[31]
System.out.println("[32] テキストデータ = " + new String(ch, offset, length));
}
public void endElement(String uri, String localName, String qName) {//[40]
System.out.println("[41] 要素終了 = " + qName);
startItem = false;//[42]
}
public void endDocument(){//[50]
System.out.println("[51] ドキュメント終了");
}
}
実行結果
[11] ドキュメント開始 [21] 要素開始 = receipt [21] 要素開始 = item [32] 内容 = りんご [41] 要素終了 = item [21] 要素開始 = item [32] 内容 = みかん [41] 要素終了 = item [41] 要素終了 = receipt [51] ドキュメント終了
プログラムの説明
- [1] 実行のためのmain()メソッド定義。
- [2]-[4] 構文解析する。(セクション:SAX API仕様→SAX Parserの準備をする→「ステップ1から3」を参照)
- [10][11] ドキュメント開始イベントで、「ドキュメント開始」を表示する。
- [20][21] 要素開始イベントで、「要素開始」を表示する。
- [22][23] もし要素名がitemならば、startItemにtrueを設定する。
- [30][31] startItemがtrueならば、内容を表示する。
- [40][41] 要素終了イベントで、「要素終了」を表示する。
- [42] startItemにfalseを設定する。
- [50][51] ドキュメント終了イベントで、「ドキュメントの終了」を表示する。
SAXで複雑なXMLを扱うサンプルプログラム
このサンプルプログラムは、少し複雑なXMLドキュメントを読み込んで、その要素を表示する
XMLドキュメントの中にお店と商品の内容が含まれている。また、お店には属性がある。
<?xml version="1.0" encoding="UTF-8"?>
<receipt>
<shop id="0123">ABC店</shop>
<items>
<item>りんご</item>
<item>みかん</item>
</items>
</receipt>
このサンプルプログラムもSAXを使っているので、レシートの一行を読むたびにイベントに対応したメソッドが呼び出される。詳細を知るには、プログラムの説明とSAX API仕様を照らし合わせながら学ぶ必要がある。
このサンプルプログラムもフィルターをかけて、名前がshopとitemの要素の開始と終了の間に内容だけを表示している。
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.File;
import java.io.IOException;
public class XmlSaxComplexReader extends DefaultHandler{
boolean startItem = false;
public static void main(String[] args) throws IOException, ParserConfigurationException, SAXException {//[1]
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();//[2]
SAXParser saxParser = saxParserFactory.newSAXParser();//[3]
saxParser.parse(new File("C:\\temp\\receipt_complex.xml"), new XmlSaxComplexReader());//[4]
}
public void startDocument() {//[10]
System.out.println("[11] ドキュメント開始");
}
public void startElement(String uri, String localName, String qName, Attributes attributes) {//[20]
System.out.println("[21] 要素開始 = " + qName);//[21]
if (qName.equals("shop")) {//[22]
startItem = true;//[23]
return;//[24]
}
if (qName.equals("item")) {//[25]
startItem = true;//[26]
return;//[27]
}
}
public void characters(char[] ch, int offset, int length) {//[30]
if (startItem)//[31]
System.out.println("[32] 内容 = " + new String(ch, offset, length));
}
public void endElement(String uri, String localName, String qName) {//[40]
System.out.println("[41] 要素終了 = " + qName);
startItem = false;//[42]
}
public void endDocument(){//[50]
System.out.println("[51] ドキュメント終了");
}
}
実行結果
[11] ドキュメント開始 [21] 要素開始 = receipt [21] 要素開始 = shop [24] 属性:id=0123 [32] 内容 = ABC店 [41] 要素終了 = shop [21] 要素開始 = items [21] 要素開始 = item [32] 内容 = りんご [41] 要素終了 = item [21] 要素開始 = item [32] 内容 = みかん [41] 要素終了 = item [41] 要素終了 = items [41] 要素終了 = receipt [51] ドキュメント終了
プログラムの説明
- [1] 実行のためのmain()メソッド定義。
- [2]-[4] 構文解析する。(セクション:SAX API仕様→SAX Parserの準備をする→「ステップ1から3」を参照)
- [10][11] ドキュメント開始イベントで、「ドキュメント開始」を表示する。
- [20][21] 要素開始イベントで、「要素開始」を表示する。
- [22]-[26] もし要素名がshopならば、属性を表示して、startItemにtrueを設定する。
- [25]-[27] もし要素名がitemならば、startItemにtrueを設定する。
- [30][31] startItemがtrueならば、内容を表示する。
- [40][41] 要素終了イベントで、「要素終了」を表示する。
- [42] startItemにfalseを設定する。
- [50][51] ドキュメント終了イベントで、「ドキュメントの終了」を表示する。
DOM API仕様
DOMはXMLを扱うためのAPI仕様である。この仕様では、XMLによって書かれた文書全体をドキュメントとし、そのドキュメントの構造をノードから構成されるノードツリーとしている。ドキュメントを構成する要素がノードになる。
こうなると、言葉がこんがらがってくる。XMLの世界と、それを扱うDOMの世界の言葉を対応させて考えなくていけない。
DOMが用意しているAPI仕様を、最初からノードの情報を取り出すまでのステップを追ってみてみよう。
ドキュメントを取得する
ステップ1:DOMのAPIを使うために最初に使うのが、DocumentBuilderFactoryクラスのstaticメソッドnewInstance()である。
DocumentBuilderFactory.newInstance()
|
戻り値の型 |
public static DocumentBuilderFactory |
|
内容 |
DocumentBuilderFactoryの新しいインスタンスを得る。このstaticメソッドは新しいインスタンスを生成する。
メソッドが提供されているクラス:DocumentBuilderFactoryクラスは、パッケージjavax.xml.parsersにある。 アプリケーションが、XMLドキュメントからDOMオブジェクトツリーを作るパーサーを得ることを可能にするFactory APIを定義している。
戻り値:DocumentBuilderFactoryの新しいインスタンス。 例外: FactoryConfigurationError – サービス構成エラーか、もし実装がされていないか、インスタンスが生成できない場合。 |
ステップ2:DocumentBuilderFactoryのインスタンスからDocumentBuilderのインスタンスを得るためにメソッドnewDocumentBuilder()を呼び出す。
newDocumentBuilder ()
|
戻り値の型 |
public abstract DocumentBuilder |
|
内容 |
現在の製造設定パラメータを使ってDocumentBuilderの新しいインスタンスを生成する。
戻り値:DocumentBuilderの新しいインスタンス。 例外: ParserConfigurationException – DocumentBuilderが要求された構成情報を満足するものを生成することができない場合。 |
ステップ3:DocumentBuilderのインスタンスから、ドキュメントを得るためにメソッドparse()を呼び出す。
parse(File f)
|
戻り値の型 |
public Document |
|
内容 |
XMLドキュメントとして与えられたファイルの内容を構文解析して、DOMドキュメントオブジェクトを返す。もし、ファイルがnullであれば、IllegalArgumentExceptionを発生させる。
メソッドが提供されているクラス:DocumentBuilderクラスは、パッケージjavax.xml.parsersにある。XMLドキュメントからDOMドキュメントオブジェクトを得るためのAPIを定義する抽象クラスである。このクラスを使って、プログラマーはXMLからドキュメントを得ることができる。
引数:f – 構文解析すべきXMLを含んでいるファイル。 戻り値:DOMドキュメントオブジェクト。 例外: IOException – IOエラーが発生した場合。 SAXException – 構文解析エラーが発生した場合。 IllegalArgumentException – ファイルがnullの場合。 |
ドキュメントからノードを取得する
ステップ4:ドキュメントから、エレメントノードを得るためにメソッドgetDocumentElement ()を呼び出す。
getDocumentElement ()
|
戻り値の型 |
Element |
|
内容 |
これは、ドキュメントのドキュメントエレメントにあたる子ノードに直接アクセスすることを許す便利な属性である。
メソッドが提供されているクラス:Documentクラスは、パッケージorg.w3c.domにある。Documentインターフェースクラスは、HTMLまたはXMLの完全なドキュメント表現している。概念的としては、ドキュメントツリーの根であり、ドキュメントデータに対する最初のアクセスを提供している。 |
ノードから様々な値を取得する
Nodeクラスは、パッケージorg.w3c.domにある。Nodeインターフェースは、完全なDOMのための最初のデータ型である。それは、ドキュメントツリーのひとつのノードを表現している。
Nodeインターフェースを実装している全てのオブジェクトが子ノードを扱うためのメソッドを持っているが、全てのオブジェクトに子ノードがあるわけではない。例えば、テキストノードは子ノードを持っていないかもしれない。そしてそのようなノードに子ノードを追加しようとすると、DOMExceptionを発生させる結果になる。
Nodeインターフェースのメソッドの仕様は次の通りである。
getFirstChild ()
|
戻り値の型 |
Node |
|
内容 |
このノードの最初の子ノード。もしそのようなノードがなければ、nullを戻す。 |
getNodeType()
|
戻り値の型 |
short |
|
内容 |
既に定義されている基本的なオブジェクトの型を表現しているコード。 |
getNodeValue()
|
戻り値の型 |
String |
|
内容 |
このノードの値で、その型に依存している;詳細は、仕様の中のテーブルを参照。それがnullであると定義されている場合、このノードが読み取り専用である場合も含めて、設定することは何の影響も与えない。
例外: DOMException - DOMSTRING_SIZE_ERR:実装プラットフォーム上でDOMString変数にフィットする文字より多い文字が戻ってきた場合。 |
getNextSibling ()
|
戻り値の型 |
Node |
|
内容 |
このノードに接して続くノード。もし、そのようなノードがなければ、nullを返す。 |
DOMの仕様に基づいていくつかのライブラリが提供されているが、このサンプルでは、JDKに含まれているJAXP( Java API for XML Processing)を使っている。
DOMでシンプルなXMLを扱うサンプルプログラム
このサンプルで扱うXMLドキュメントはレシートで、その中の商品が次のようにひとつなっている。
<?xml version="1.0" encoding="UTF-8"?> <item>りんご</item>
このサンプルプログラムはこのレシートを読み込んで、その要素を表示する。DOMを使っているので、最初に解析が行われて、その結果から要素を取り出す流れになっている。詳細を知るには、プログラムの説明とDOM API仕様を照らし合わせながら学ぶ必要がある。
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import java.io.File;
public class XmlDomSimpleReader {
public static void main(String args[]) throws Exception{
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();///[1]
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();///[2]
Document document = documentBuilder.parse(new File("C:\\temp\\receipt_one_element.xml"));//[3]
Node elementNode = document.getDocumentElement();//[4]
Node textNode = elementNode.getFirstChild();//[5]
if (textNode.getNodeType()==Node.TEXT_NODE) {//[6]
System.out.println("[7] テキストノード = " + textNode.getNodeValue());
}
}
}
実行結果
[7] テキストノード = りんご
プログラムの説明
- [1]-[3] ドキュメント取得する。(セクション:DOM API仕様→ドキュメント取得する→「ステップ1から3」を参照)
- [4] ドキュメントからelementNodeを取得する。(セクション:DOM API仕様→「ドキュメントからノードを取得する」を参照)
- [5] ノードelementNodeからさ最初の子ノードtextNodeを取得する。(セクション:DOM API仕様→「ノードから様々な値を取得する」を参照)
- [6] textNodeの型がテキストノードであることをチェックする。
- [7] textNodeの値を表示する。
DOMでXMLを扱うサンプルプログラム
このサンプルで扱うXMLドキュメントはレシートで、その中の商品が次のようにふたつになっている。
<?xml version="1.0" encoding="UTF-8"?>
<receipt>
<item>りんご</item>
<item>みかん</item>
</receipt >
これを、DOMのノードツリーで考えると次のようになる。

このサンプルプログラムは、レシートの中の要素をその数だけ表示する。プログラムコードの中で、ノードの変数名とXML要素名を対応させている。この点を注意してコードを読めば、レシートの要素と照らし合わせながら処理の流れを理解できるようになっている。
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;
public class XmlDomNodesReader {
public static void main(String args[]) throws Exception{
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();///[1]
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();///[2]
Document document = documentBuilder.parse(new File("C:\\temp\\receipt_two_elements.xml"));//[3]
Node receptNode = document.getDocumentElement();//[4]
Node itemNodes = receptNode.getFirstChild();//[5]
while(itemNodes != null) {//[6]
Node textNode = itemNodes.getFirstChild();//[7]
if (checkTextNode(textNode)) {//[8]
System.out.println("[9] テキストノード = " + textNode.getNodeValue());
}
itemNodes = itemNodes.getNextSibling();//[10]
}
}
private static boolean checkTextNode(Node node) {//[20]
if (node == null) return false;//[21]
if (node.getNodeType() == Node.TEXT_NODE)//[22]
return true;//[23]
return false;//[24]
}
}
実行結果
[7] テキストノード = りんご [7] テキストノード = みかん
プログラムの説明
- [1]-[3] ドキュメント取得する。(セクション:DOM API仕様→ドキュメント取得する→「ステップ1から3」を参照)
- [4] ドキュメントからreceiptNodeを取得する。(セクション:DOM API仕様→「ドキュメントからノードを取得する」を参照)
- [5] ノードreceiptNodeから最初の子ノードitemNodeを取得する。(セクション:DOM API仕様→「ノードから様々な値を取得する」を参照)
- [6]-[10] itemNodeがnullになるまで、同じ親ノードを持つ子ノードを取得する。
- [7] itemNodeの子ノードをtextNodeとして取得する。
- [8] textNodeの型がテキストノードであることをチェックする。
- [9] textNodeの値を表示する。
- [20] メソッドcheckTextNode()を定義する。
- [21] nodeがnullならば、falseを戻す。
- [22]-[23] nodeの型がテキストノードであるならば、trueを戻す。
- [24] falseを戻す。
DOMで複雑なXMLを扱うサンプルプログラム
このサンプルで扱うXMLドキュメントはレシートで、その中のデータが大きく分けて次のようにお店と商品のふたつになっている。
<?xml version="1.0" encoding="UTF-8"?>
<receipt>
<shop id="0123">ABC店</shop>
<items>
<item>りんご</item>
<item>みかん</item>
</items>
</receipt >
これを、DOMのノードツリーで考えると次のようになる。
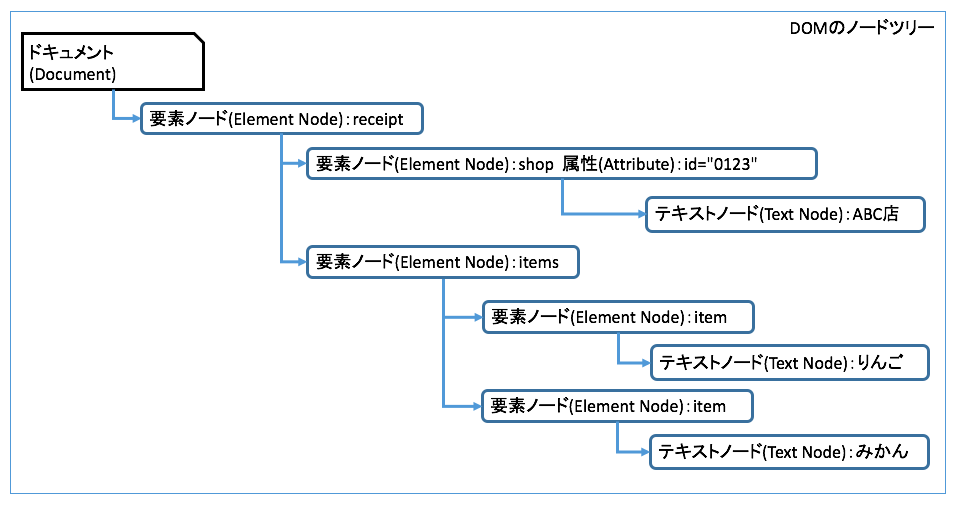
このサンプルプログラムは、レシートの中の要素をすべて要素ごとに表示する。プログラムコードの中で、ノードの変数名や属性名とXMLの要素名や属性名を対応させている。この点を注意してコードをみれば、プログラムの処理の流れを理解できるようになっている。
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NamedNodeMap;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;
public class XmlDomComplexReader {
public static void main(String args[]) throws Exception{
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();///[1]
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();///[2]
Document document = documentBuilder.parse(new File("C:\\temp\\receipt_complex.xml"));//[3]
Node receiptNode = document.getDocumentElement();//[4]
Node elementNodes = receiptNode.getFirstChild();//[5]
while(elementNodes != null) {//[6]
String elementNodesNodeName = elementNodes.getNodeName();//[7]
switch (elementNodesNodeName) {//[8]
case "shop"://[9]
printNode(elementNodesNodeName, elementNodes);//[10]
printAttribute("id", elementNodes);//[11]
break;//[12]
case "items"://[13]
Node itemNodes = elementNodes.getFirstChild();//[14]
while(itemNodes != null) {//[15]
printNode(elementNodesNodeName, itemNodes);//[16
itemNodes = itemNodes.getNextSibling();//[17]
}
break;//[18]
}
elementNodes = elementNodes.getNextSibling();//[19]
}
}
private static void printNode(String nodeName, Node node) {//[30]
Node textNode = node.getFirstChild();//[31]
if (checkTextNode(textNode)) {//[32]
System.out.println("[33] ノード = " + nodeName);
System.out.println("[34] テキストノード = " + textNode.getNodeValue());
}
}
private static void printAttribute(String id, Node node) {//[40]
NamedNodeMap attributes = node.getAttributes();//[41]
if (attributes!=null) {//[42]
Node attribute = attributes.getNamedItem(id);//[43]
System.out.println("[44] " + id + " = " + attribute.getNodeValue());
}
}
private static boolean checkTextNode(Node node) {//[50]
if (node == null) return false;//[51]
if (node.getNodeType() == Node.TEXT_NODE)//[52]
return true;//[53]
return false;//[54]
}
}
実行結果
[33] ノード = shop [34] テキストノード = ABC店 [44] id = 0123 [33] ノード = items [34] テキストノード = りんご [33] ノード = items [34] テキストノード = みかん
プログラムの説明
- [1]-[3] ドキュメント取得する。(セクション:DOM API仕様→ドキュメント取得する→「ステップ1から3」を参照)
- [4] ドキュメントからreceiptNodeを取得する。(セクション:DOM API仕様→「ドキュメントからノードを取得する」を参照)
- [5] ノードreceiptNodeから最初の子ノードelementNodesを取得する。(セクション:DOM API仕様→「ノードから様々な値を取得する」を参照)
- [6]-[19] elementNodesがnullになるまで、同じ親ノードを持つ子ノードを取得する。
- [7] elementNodesの名前を取得する。
- [7]-[12] elementNodesの名前がshopであれば、elementNodesのノードの情報と属性を表示する。
- [13]-[18] elementNodesの名前がitemsであれば、elementNodesの子ノードitemNodesの情報を表示する。
- [30] メソッドprintNode ()を定義する。
- [31] 引数で与えられたノードの子ノードをtextNodeとして取得する。
- [32] textNodeの型がテキストノードであることをチェックする。
- [33] textNodeの値を表示する。
- [40] メソッドprintAttribute ()を定義する。
- [41][42] ノードが引数で与えられた属性を持っているかをチェックする。
- [42] 属性があれば、その属性の値を表示する。
- [50] メソッドcheckTextNode()を定義する。
- [51] nodeがnullならば、falseを戻す。
- [52]-[23] nodeの型がテキストノードであるならば、trueを戻す。
- [54] falseを戻す。
まとめ
このページではXMLと、JavaでXMLを扱う方法についてお伝えしてきた。
かなり細かくお伝えしたので長くなってしまったが参考にしていただければと思う。


