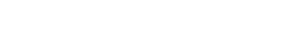

joinはテキストファイルを同じ項目同士で結合するコマンドだ。
目次
- 1 joinコマンドの基本
- 2 joinコマンドのオプションたち
- 2.1 オプションの一覧
- 2.2 -aオプション:指定したファイルの行はすべて表示する
- 2.3 -iオプション:(--ignore-caseオプション):項目名を検索する時大文字と小文字を区別しない
- 2.4 -jオプション:一致に使う項目を指定する
- 2.5 -oオプション:出力するフィールドを指定する
- 2.6 -1オプション:1つめに指定したファイルで一致に使う項目を指定する
- 2.7 -2オプション:2つめに指定したファイルで一致に使う項目を指定する
- 2.8 -eオプション:指定したフィールドがなければ任意の文字列を表示するする
- 2.9 -tオプション:区切り文字を指定する
- 2.10 -vオプション:一致しない行を出力する
- 2.11 --check-orderオプション:一致させる項目が昇順に並んでいるかチェックする
- 2.12 --nocheck-orderオプション:一致させる項目が昇順に並んでいるかチェックしない
- 2.13 --headerオプション:ファイルの1行目はフィールド名として扱う
- 3 join関連コマンド
joinコマンドの基本
コマンドの基本動作
使い方は、次のとおりだ。
$ join ファイル名1 ファイル名2
ファイルitemname.txtとitemcount.txtを結合する場合は、次のコマンドだ。
$ join itemname.txt itemcount.txt
ファイルitemname.txtとitemcount.txtを結合した結果を表示した。
結果は比較する項目において、両方のファイルに存在するもののみを表示する。
また、比較する項目は数値である必要はないが、昇順に並んでいる必要がある。
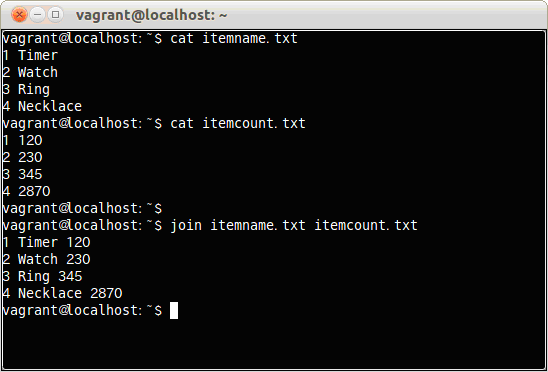
ファイルitemcount-b.txtには、番号1と3の2行しかない。
このitemcount-b.txtとitemname.txtを次のコマンドで結合する。
$ join itemname.txt itemcount-b.txt
ファイルitemname.txtとitemcount-b.txt結合し、両方にある番号1と3のみの結果を表示した。
また、1つのファイルの中に同じ番号が入っていても、もう一方のファイルと番号で一致させる。
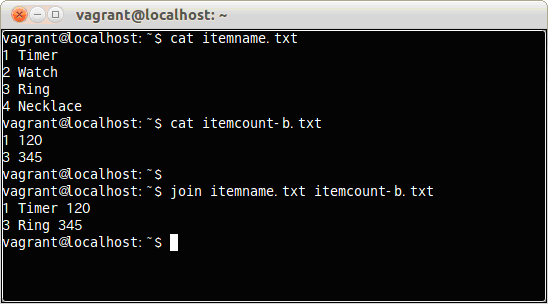
例えば、商品管理をする上で、2つの商品データとして商品番号と商品名と単価の入っているファイルpendata.datと、4つの売上データとして商品番号と販売数が入っているファイルpensale.datを結合する。
$ join pendata.dat pensale.dat
このように2つの一覧表を結合することも可能だ。
joinコマンドのオプションたち
オプションの一覧
後から詳細をご紹介するが、まずは一覧で見てみよう。
オプション -a
指定したファイルの行はすべて表示する
オプション -i(オプション--ignore-case)
項目名を検索する時大文字と小文字を区別しない
オプション -j
一致に使う項目を指定する
オプション -o
出力するフィールドを指定する
オプション -1
1つめに指定したファイルで一致に使う項目を指定する
オプション -2
2つめに指定したファイルで一致に使う項目を指定する
オプション -e
指定したフィールドがなければ任意の文字列を表示する
オプション -t
区切り文字を指定する
オプション -v
一致しない行を出力する
オプション--check-order
一致させる項目が昇順に並んでいるかチェックする
オプション--nocheck-order
一致させる項目が昇順に並んでいるかチェックしない
オプション--header
ファイルの1行目はフィールド名として扱う
-aオプション:指定したファイルの行はすべて表示する
指定したファイルの行をすべて表示する書式は次のとおりだ。
$ join -a すべての行を表示するファイル番号 ファイル名1 ファイル名2
ファイルitemname.txtとitemcount-b.txtを結合し、ファイルitemname.txtのすべての行を表示する場合は、次のコマンドだ。
$ join -a 1 itemname.txt itemcount-b.txt
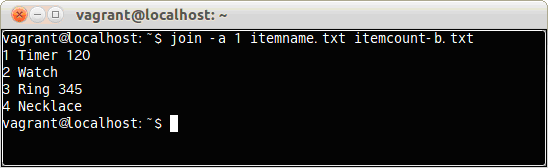
ファイルitemname.txtとitemcount-b.txtを結合し、ファイルitemname.txtのすべての行を表示した。
すべての行が表示されたが、WatchとNecklaceの数値が表示されていない。
両方のファイルに存在している行をすべて表示することもできる。
ファイルitemcount-c.txtは、番号5の1行のみだ。
このファイルと、番号が1から4までのファイルの両方にある行を次のコマンドで表示する場合は、次のように-aオプションを2つ指定する。
$ join -a 1 -a 2 itemname.txt itemcount-c.txt
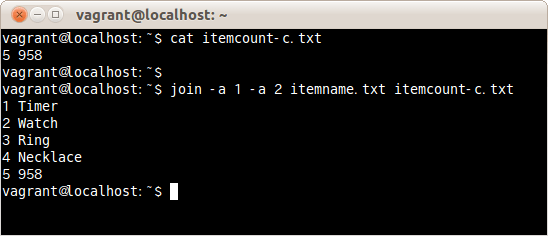
ファイル itemname.txtとitemcount-c.txtの両方にある番号1から5までの行に結合され、表示された。
-iオプション:(--ignore-caseオプション):項目名を検索する時大文字と小文字を区別しない
一致に使う項目は数値である必要はない。
もし、文字列を使う場合は、オプションなしでは大文字、小文字を区別する。
項目名を検索する時大文字と小文字を区別しないときは-iオプションを指定する。
書式は次のとおりだ。
$ join -i ファイル名1 ファイル名2
項目名を検索する時大文字と小文字を区別せずにファイルmember.datとbirthday.datを結合する場合は、次のコマンドだ。
$ join -i member.dat birthday.dat
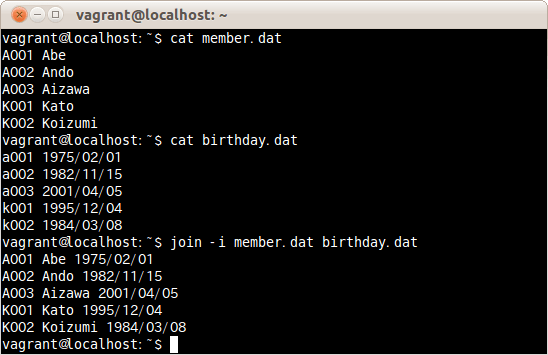
項目名を検索する時大文字と小文字を区別せずにファイルmember.datとbirthday.datを結合した。
-jオプション:一致に使う項目を指定する
オプションなしでは一致に使う項目は1番目のフィールドを使うが、-jオプションを使うことで任意のフィールドを使うことができる。
フィールドは左から順の番号で指定する。
書式は次のとおりだ。
$ join -j 項目番号 ファイル名1 ファイル名2
一致に使う項目を2番目のフィールドとして指定しファイルpensale2.datとpendata2.datを結合する場合は、次のコマンドだ。
$ join -j 2 pensale2.dat pendata2.dat
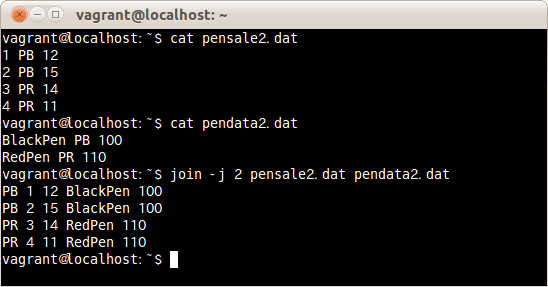
一致に使う項目を2番目のフィールドとして指定しファイルpensale2.datとpendata2.datを結合した。
-oオプション:出力するフィールドを指定する
表示出力するフィールドを指定する。
指定は、1つめのファイルか2つめのファイルかのファイル番号のあと、「.(ピリオド)」、さらにフィールド番号という形で指定する。
書式は次のとおりだ。
$ join -o ファイル番号.フィールド番号 ファイル名1 ファイル名2
出力するフィールドを1つめのファイルの2つめのフィールドを指定しファイルpensale.datとpendata.datを結合する場合は、次のコマンドだ。
$ join -o 1.2 pensale.dat pendata.dat
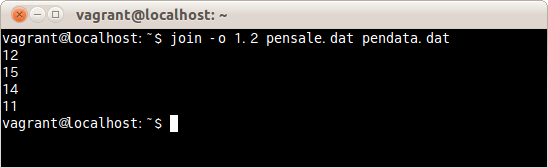
出力するフィールドを1つめのファイルの2つめのフィールドを指定しファイルpensale.datとpendata.datを結合した。
1項目だけでなく、複数のフィールドを選択する場合は{ }で囲んで「,(カンマ)」で区切る。
出力するフィールドを2つめのファイルの2つめと3つめのフィールドを指定しファイルpensale.datとpendata.datを結合する場合は、次のコマンドだ。
$ join -o 2.{2,3} pensale.dat pendata.dat
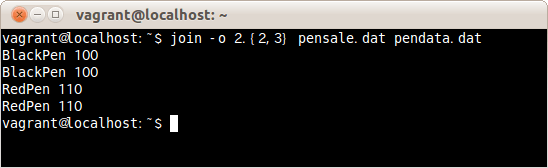
出力するフィールドを2つめのファイルの2つめと3つめのフィールドを指定しファイルpensale.datとpendata.datを指定しファイルpensale.datとpendata.datを結合した。
複数項目を表示する方法は、「ファイル番号.フィールド番号」を続ける書式でもできる。
出力するフィールドを1つめのファイルの1つめのフィールドと2つめのファイルの3つめのフィールドとを指定しファイルpensale.datとpendata.datを結合する場合は、次のコマンドだ。
$ join -o 1.1 2.3 pensale.dat pendata.dat
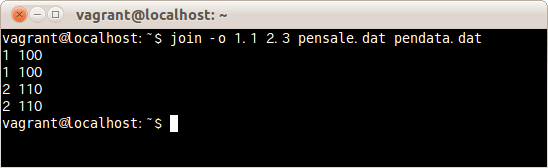
出力するフィールドを1つめのファイルの1つめのフィールドと2つめのファイルの3つめのフィールドとを指定しファイルpensale.datとpendata.datを結合した。
-1オプション:1つめに指定したファイルで一致に使う項目を指定する
-jオプションで一致する項目を指定することができるが、1つめのファイルと2つめのファイルとも同じ位置の項目を使うことになる。
-1オプションでは、1つめのファイルで使う項目のみを独立して指定することが可能だ。
1つめのファイルで一致に使う項目を指定するする書式は次のとおりだ。
$ join -1 項目番号 ファイル名1 ファイル名2
1つめのファイルで一致に使う項目を2項目目に指定しファイルpensale3.datとpendata3.datを結合する場合は、次のコマンドだ。
$ join -1 2 pensale3.dat pendata3.dat

1つめのファイルで一致に使う項目を2項目目に指定しファイルpensale3.datとpendata3.datを結合した。
-2オプション:2つめに指定したファイルで一致に使う項目を指定する
-1オプションと同様に、2つめのファイルで使う項目のみを独立して指定する。
2つめに指定したファイルで一致に使う項目を指定するする書式は次のとおりだ。
$ join -2 項目番号 ファイル名1 ファイル名2
2つめのファイルで一致に使う項目を3項目目に指定しファイルpensale4.datとpendata4.datを結合する場合は、次のコマンドだ。
$ join -2 2 pensale4.dat pendata4.dat
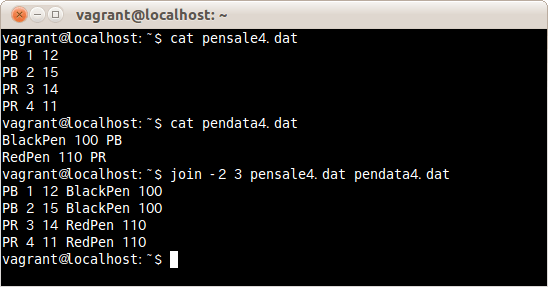
2つめのファイルで一致に使う項目を3項目目に指定しファイルpensale4.datとpendata4.datを結合した。
-eオプション:指定したフィールドがなければ任意の文字列を表示するする
指定したフィールドがなければ任意の文字列を表示する。
このオプションは、-jオプションや-1オプションや-2オプションのような一致項目を指定するオプションか、出力項目を指定する-oオプションと組み合わせて利用する。
書式は次のとおりだ。
$ join 他のオプション -e 文字列 ファイル名1 ファイル名2
わざとエラーになるように、実在しない項目番号5を指定し、エラーの場合はxxxと表示されるようにし、ファイルpendata.datとpensale.datを結合する場合は、次のコマンドだ。
$ join -j 5 -a 1 -e xxx pendata.dat pensale.dat
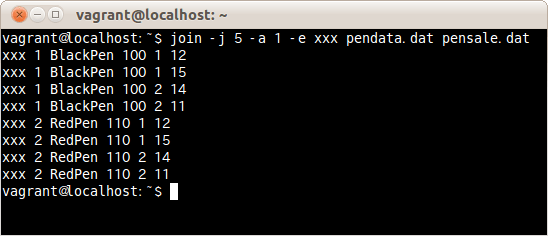
指定した項目番号5がないので、すべての行で結合できず、xxxを表示した。
結合ができないことで、どの行を表示するか明確ではないので、すべての組み合わせパターンを表示している。
-eオプションを設定し、かつ、-aオプションですべての行を表示し、-oオプションで1ファイルの2項目と2ファイルの1項目目を表示してみる。
$ join -a 1 -a 2 -o 1.2 2.1 -e xxx itemname.txt itemcount-c.txt
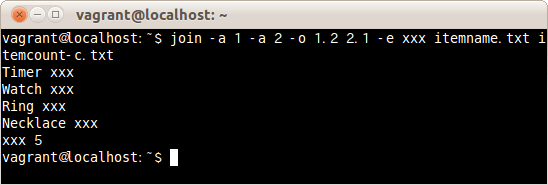
存在しないデータの箇所にxxxと表示した。
-tオプション:区切り文字を指定する
オプションなしでは区切り文字は半角空白が適用される。
区切り文字を指定するする書式は次のとおりだ。
$ join -t 区切り文字 ファイル名1 ファイル名2
区切り文字を-に指定しファイルpendata5.datとpensale5.datを結合する場合は、次のコマンドだ。
$ join -t - pendata5.dat pensale5.dat
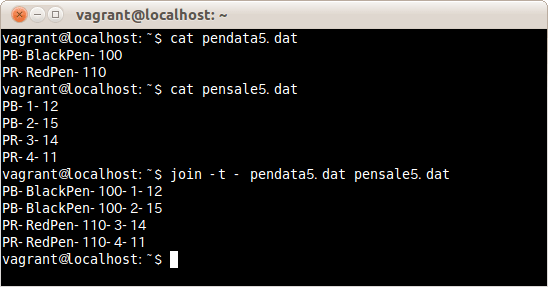
区切り文字を-に指定しファイルpendata5.datとpensale5.datを結合した。
-vオプション:一致しない行を出力する
オプションなしでは一致しない行は表示しないが、-vオプションは一致しない行だけを表示する。
一致しない行を出力する書式は次のとおりだ。
$ join -v 基準となるファイル番号 ファイル名1 ファイル名2
ファイルitemname.txtとitemcount-b.txtの一致しない行を出力する場合は、次のコマンドだ。
$ join -v itemname.txt itemcount-b.txt
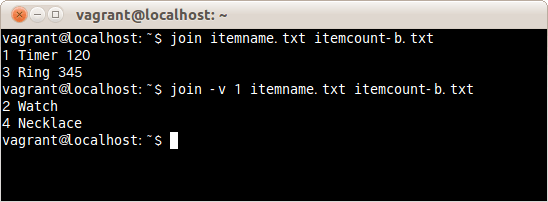
オプションなしでは、一致した1行目と3行目を表示した。
-vオプションを指定すると、一致しない2行目と4行目を出力した。
--check-orderオプション:一致させる項目が昇順に並んでいるかチェックする
一致させる項目が昇順に並んでいるかチェックする。
オプションなしではチェックする。
書式は次のとおりだ。
$ join --check-order ファイル名1 ファイル名2
一致させる項目が昇順に並んでいるかチェックしファイルdata1.datとdata2.datを結合する場合は、次のコマンドだ。
$ join --check-order data1.dat data2.dat
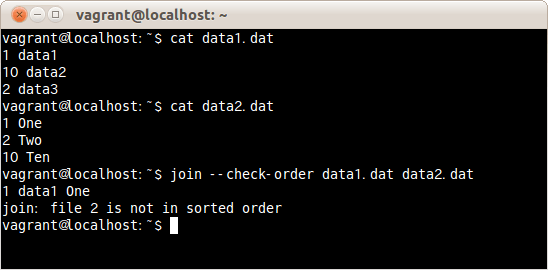
一致させる項目が昇順に並んでいるかチェックしファイルdata1.datとdata2.datを結合した。
ファイルdata1.datは2行目よりも3行目が小さい、並べ替えがきちんとされていないデータだ。
1行目はきちんと結合できたが、2行目以降はエラーのため、結合できない。
--nocheck-orderオプション:一致させる項目が昇順に並んでいるかチェックしない
--check-orderオプションに対し、並べ替え順のチェックを行わないオプションだ。
一致させる項目が昇順に並んでいるかチェックしない書式は次のとおりだ。
$ join --nocheck-order ファイル名1 ファイル名2
一致させる項目が昇順に並んでいるかチェックせず、ファイルdata1.datとdata2.datを結合するする場合は、次のコマンドだ。
$ join --nocheck-order data1.dat data2.dat
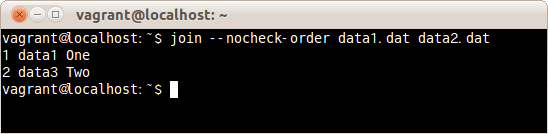
一致させる項目が昇順に並んでいるかチェックしておらず、エラーメッセージが表示されなくなった。
また、2行目がファイルdata2.datの3行目と結合してしまっており、3行目は結合できなかった。
エラーは出なくなるが、間違った結合をする場合もあるので注意が必要だ。
--headerオプション:ファイルの1行目はフィールド名として扱う
ファイルの1行目はフィールド名として扱う書式は次のとおりだ。
$ join --header ファイル名1 ファイル名2
ファイルの1行目はフィールド名として扱いファイルmember-2.datとbirthday-2.datを結合する場合は、次のコマンドだ。
$ join --header member-2.dat birthday-2.dat
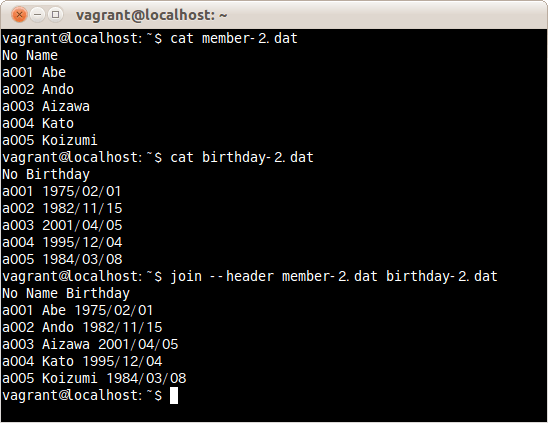
ファイルの1行目はフィールド名として扱いファイルmember-2.datとbirthday-2.datを結合した。
この2ファイルは1行目を項目名として設定しているが、1項目目が同じNoというフィールドがあるために、オプションなしでも一致した行として表示される。
では、わざと一致させないために、2ファイル目にBirthdayとだけ書いたファイルbirthday-3.datとファイルmember-2.datを結合する。
$ join --header member-2.dat birthday-3.dat
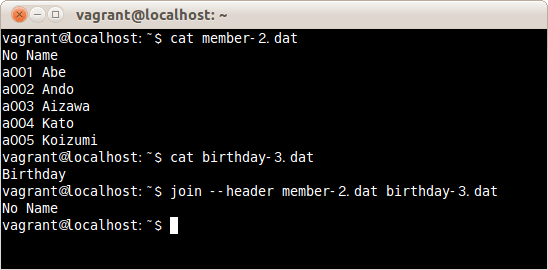
1ファイル目と2ファイル目は一致する内容はないはずなので、何も表示されないはずだが、1行目をフィールド名として扱っているため、必ず表示される。
join関連コマンド
最後にjoinコマンドに関連して、基本的なテキストファイルを操作するコマンドも紹介しておく。
catコマンド
テキストファイルを縦方向に結合する。
pasteコマンド
テキストファイルを横方向に結合する。
joinコマンドと違い、同じ項目で結合するのではなく、単純に横方向に結合するだけだ。
sortコマンド
テキストファイルを並べ替える。
sedコマンド
行を置き換える。
grepコマンド
行を抽出する。
uniqコマンド
重複行を削除する。
まとめ
joinコマンドはSQLにおけるテーブル同士をつなぐ、JOIN文にそっくりだ。
関連コマンドを組み合わせることで、テキストファイルを使ったデータベースを高速に動作させることができる。
大量のデータファイルの編集、結合、抽出を行うときには非常に便利なコマンドだ。



コメント