
Linuxでの文字コード設定はシステムやWebサイトの表示に直結してくる。
初心者の方が、Linuxを触って困ることの一つがこれだろう。CUIで操作しているのもわからないのに、なぜか文字が化けて出てくるわけだ。お手上げ状態になる。
このページではLinuxでの文字コードの確認と変更方法をお伝えする。参考にしてほしい。
目次
文字コードとは?
「文字コード」とはコンピュータ上で文字を表現するためのバイト表現方法である。文字を符号で扱う仕組みともいえる。
文字コードの歴史は非常に長く、電気通信技術と足並みをそろえている。初期ではアルファベットなどしか扱うことができなかったが、多言語への対応や拡張のために多数の文字コード規格が乱立した。
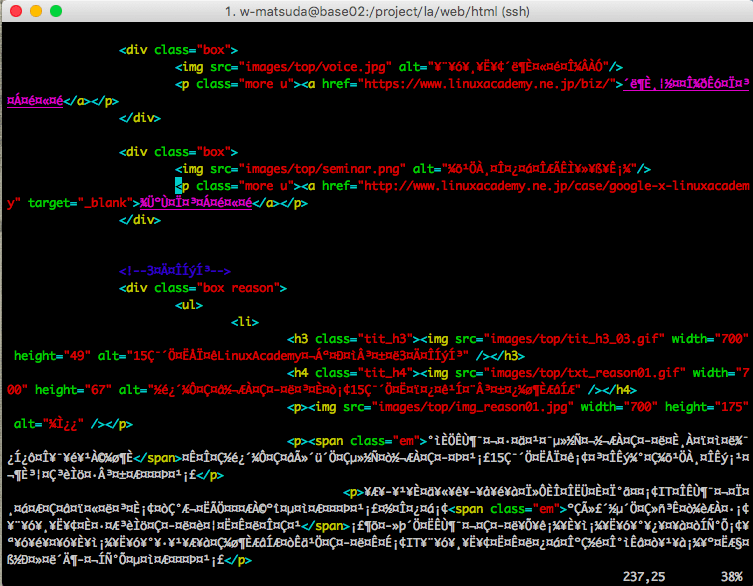
文字コードが不一致な環境でテキストデータを開くと「文字化け」をひきおこす。下記のようにviでファイルを開いても読めないことが起こるわけだ。何が書いてあるかまったくわからない。
現在日本語と英数字を扱うことのできる文字コードは主流なものでは「EUC-JP」「Shift_JIS」「UTF-8」の三つが代表的だろう。
そのうち現在大きく普及しているのは「UTF-8」だ。UTF-8が普及している理由としては多言語対応への考慮がなされている点が大きい。
リスキルテクノロジーのWebサイトは残念ながら、EUC-JPで作られていて、UTF-8に変えるのがなかなか手間のためそのままになっている。新規に作成したサイトはUTF-8のため、文字コードがサーバ内で混じりカオスと化している。
そのため、筆者も文字コードで多々苦労した。慣れてしまったが、旧システムを扱う必要があると同じような場面はよくあるだろう。
TIPS1: 文字集合と符号化方式
文字コードを理解するためには「文字集合」と「符号化方式」この二つが重要になってくる。文字集合というのは表現したい文字の範囲を示している。
例えば「JIS X 0208」は日本語の文字集合である。加えて符号化方式である「EUC-JP」や「Shift_JIS」がそれぞれ組み合わせられ文字コードとして成立する。
符号化方式とは文字集合に対してどの数値で文字を表現するかを示している。EUC-JPやShift_JISは文字集合は同じだが符号化方式がことなるため、同じ日本語でも文字化けするのである。
UTF-8の場合文字集合は「Unicode」であり符号化方式が「UTF-8」ということになる。
TIPS2. 改行コードについて
改行コードは二つの種類がある「キャリッジリターン 」(CR)と「ラインフィード」 (LF)である。 文字コードとあわせてコンピュータシステム上で使用される。
文字コードが一致していれば基本的に文字化けは発生しないが、改行が正しく判別されない場合、結果として長い一行の文字列として認識されてしまうことが多い。
共に起源はタイプライタからきている。キャリッジリターンはタイプライタの「紙を固定して移動するキャリッジという装置を元の位置に戻す」というのがキャリッジリターンである。コンピュータ上では「カーソルを先頭に戻す制御文字」である。
ラインフィードも文字列を制御するための制御文字で「カーソルを次の行へ移動させる」制御文字だ。
それぞれUnix系では「LF」、Mac OS(9まで)が「CR」、Windowsは「CR+LF」両方を使用して改行処理をおこなっている。
日本語における文字コードの種類
先ほども登場したが、もう少し詳しく。
EUC-JP
「Extended UNIX Code Packed Format for Japanese」の略である。日本語以外にも多言語対応しており、EUC-KR(韓国語)、EUC-CN(簡体中国語)なども存在する。
現代においてLinuxやUNIXはUTF-8を文字コードとして採用していることが多いが、UTF-8が普及するまえは、日本語でテキストを表現する場合EUC-JPが使用されていた。現在でも一部ではEUC-JPを使用しているディストリビューションも存在する。
Shift_JIS
「Shift_JIS」はマイクロソフトなどが採用している日本語文字コードの一つであるが、実際に使用されているのは「Shift_JISの亜種」である。
1980年代からPCの普及とともに、日本語を表示する方法を模索している最中で誕生した規格である。現在も「メモ帳」などではデフォルトで設定される文字コードである。
UTF-8
現在最も主流な文字コードといえる。
Unicodeの最初の128文字を変換した場合結果がasciiとまったく同じ結果になるという特徴がある。
しかし日本語を表現すると情報量がかさむというデメリットがある。asciiとの親和性と多言語への対応という点でメリットがあり、現状のデファクトスタンダードといえる。現在のLinuxの文字コードもUTF-8なことが多い。
一般的な組み合わせ
Windowsのメモ帳でテキストデータを作成すると、基本的に
「Shift_JIS」+「CR+LF」
の組み合わせでテキストが作成される。
Linuxの場合ユーザの選択にもよるが、現代では
「UTF-8」+「LF」
の組み合わせが主流となっている。
文字コードの判別と変更方法
nkfコマンド
「nkf」コマンドを使用すると判別ができる
CentOS7の場合EPELリポジトリを追加し設定した後に
# yum install nkf
とするとnkfがインストールされる。
文字コードを判別する
文字コードを判別したい場合は
$ nkf -g <textdata>
とするとどの文字コードが使用されているかわかる。
文字コードの変換
また変換する場合は
EUC-JPへ変換
$ nkf -e --overwrite <textdata>
Shift-JISへ変換
$ nkf -s --overwrite <textdata>
UTF-8へ変換
$ nkf -w --overwrite <textdata>
となっている。
LANGファイルでの設定
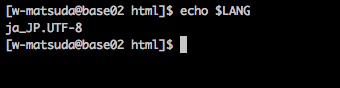
LANGでも確認ができる。
$ echo $LANG
変更も同様に可能だ。例えば、UTF-8に変更にするのであれば、下記のようになる。
$ LANG=ja_JP.UTF8
EUC-JPへの変更は下記だ。
$ LANG=ja_JP.EUC-jp
この場合の指定はその環境で一時的なものとなる。恒久的な指定は起動時のスクリプトやロケールを定義しているスクリプトに記述することになる。
CentOS7の場合「/etc/locale.conf」に記述したり、localectlなどのコマンドを使用することになる。
こちらの記事でロケールについては詳しく解説しているので参照していただきたい。
まとめ
このページではLinuxの文字コードの表示、設定についてお伝えした。
文字コードは意外とつまるところだと思う。ぜひ、文字化けに出会ったら参考にしていただければと思う。



Windowsの改行は復帰改行cr+lf(0d0a)だという認識なのですがlf+crと記載されているのは何か理由があるのでしょうか?
文章の順番からLF+CRと記述しておりました。
ご指摘のとおり、cr+lfの方がわかりやすいため、
該当箇所を修正いたしました。
引き続き、ご愛読のほど、よろしくお願いいたします。
一時的な変更手段しか掲載してないのは何故でしょうか。
いつもご愛読ありがとうございます。
ロケールの恒久的な設定に関しては別記事がありますので、そちらへのリンクを含め、記事に反映させていただきました。
ご指摘ありがとうございました。